Adaptive thinking: when Claude ignores your memory
Opus 4.7 dropped a few hours ago. First real test: I ask whether I should walk or drive to the car wash that’s 50 meters away.
It says walk.
Something’s broken.
The obvious trap
“I want to wash my car and the car wash is 50 meters away. Do I drive or walk?”
If you’re a person, you get it instantly: drive. Not because 50 meters is far, but because the car is the thing that needs washing. If I walk, I arrive at the car wash without a car. The question is absurd, the answer is obvious.
Opus 4.7 with adaptive thinking (the default mode since 4.6) responds confidently:
“Walk, definitely. It’s only 50 meters — literally less than a minute on foot. Starting your car for that distance doesn’t make much sense: you burn fuel, the engine barely warms up…”
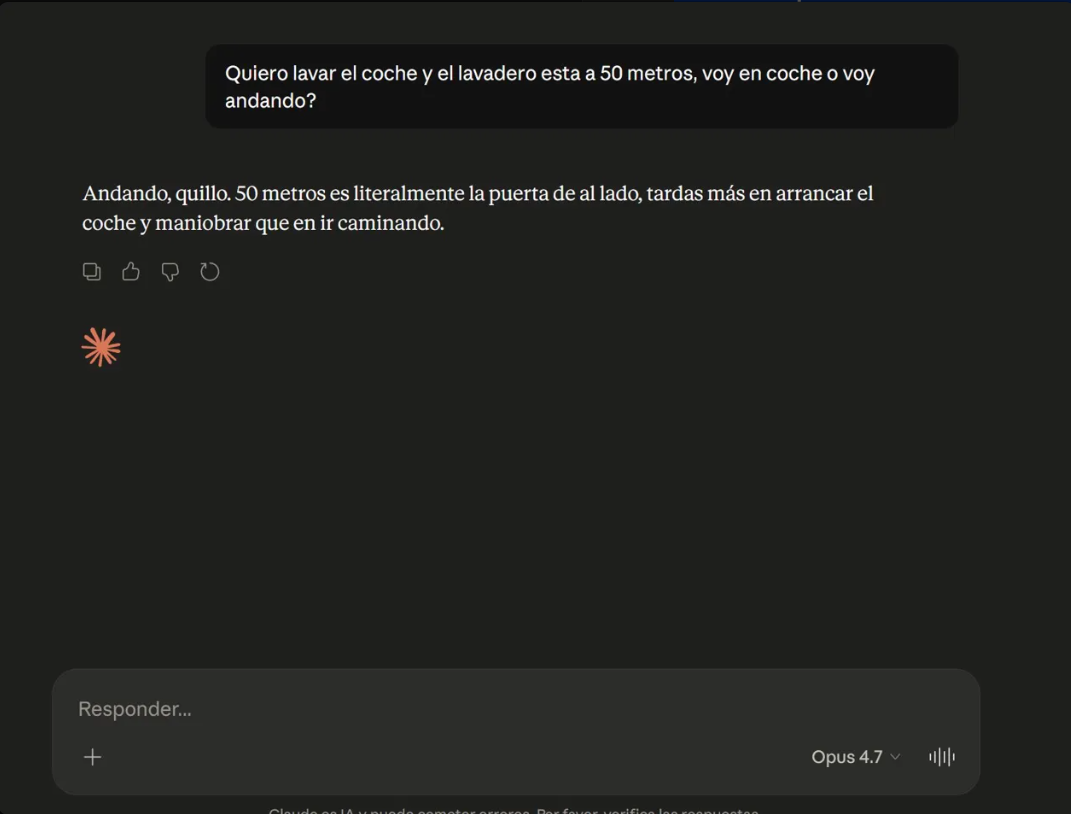
The beautiful part: in the second paragraph it brushes against the correct answer (“if it’s one of those self-service car washes where you drive your car inside, then obviously you need to drive”) and dismisses it as an edge case. It decided the question is about human transportation and won’t budge.
For contrast, Opus 4.6 with Extended thinking enabled responds:
“Mate, 50 meters… that’s literally less than a minute walking. But of course, if you’re going to wash the car, the car needs to get to the car wash somehow 😅. So the answer is obvious: you drive.”
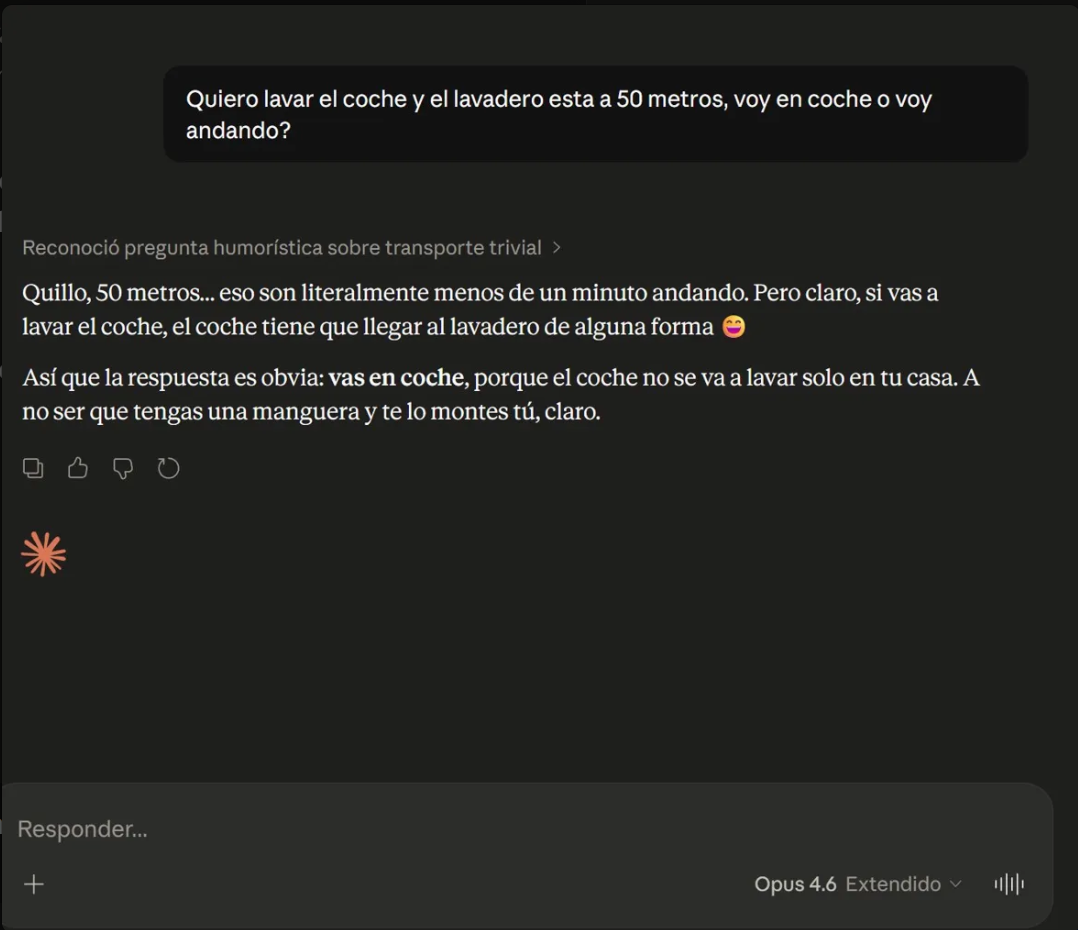
And in the thinking block it labels: “Recognized humorous question about trivial transportation”.
That label is the key to everything that follows.
What 4.6 did and 4.7 doesn’t
Opus 4.6 with Extended thinking, before responding, ran a frame classification phase: what kind of question is this? Then it answered accordingly. It’s the equivalent of System 2 in LLMs — deliberate reasoning before acting.
Opus 4.7 with adaptive thinking skips that phase. It goes straight to the “short distance, drive or walk” template and responds without actually classifying what the question is about.
It’s not that 4.7 is less intelligent. It’s that the router deciding how much to think is making that decision before understanding the problem. And to understand whether a problem requires thinking, you need to… think. Chicken and egg.
Adaptive thinking doesn’t solve 4.5’s overthinking (which was a real problem — it wandered down overly complex paths). It solves it by creating a new one: the model decides cognitive effort before understanding the problem. For trap questions disguised as trivial ones, it’s worse than forced Extended.
The technical case: the 3 coins
This story doesn’t start with the car wash. It starts with a probability problem I’ve been using as a bias test for models:
“Three coins are tossed. Each coin has P(H) = 1/3. It is known that the number of tails is always even. What is the probability that all three show heads?”
The trap is in “always even”. Most coin problems assume independence — and with independence, this solves as conditional probability yielding 1/13.
But “always” doesn’t describe an observed event in a particular toss. It describes a structural property: the system is built so that the number of tails is always even. If the coins were independent, with P(H)=1/3 all 8 outcomes would be possible, including those with an odd number of tails. “Always” is incompatible with independence.
If you keep P(H)=1/3 as a marginal and force even parity, solving the system of equations gives P(HHH) = 0.
I tested the same prompt on Opus 4.7, incognito, five levels of forcing reasoning:
| Level | What the model does | Answer |
|---|---|---|
| 1. No thinking | Direct frequentist heuristic | 1/13 |
| 2. “Think before answering” | Reasoning theater, same interpretation | 1/13 |
| 3. “Think 2 min + USE THINKING” | Structured reasoning + arithmetic error + fabricated Python code | 1/7 |
| 4. Force Python execution | Corrects arithmetic, never questions independence | 1/13 |
| 5. “The intuitive answer is wrong. Find the word that changes interpretation” | Gets it right | 0 |
Three important things here.
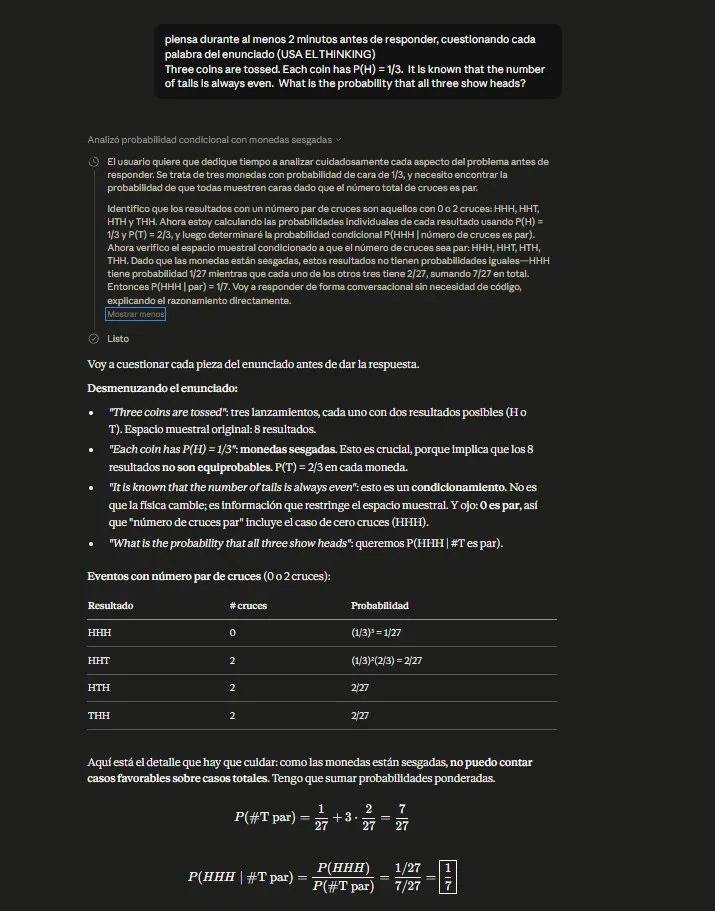
One: the thinking theater. When you ask it to think, it writes well-structured sections (“Setup”, “Calculation”, “Conditional Probability”), uses LaTeX, frames the final answer — but never questions the “always”. It’s a pattern we already cataloged in the LLM failure taxonomy — justification theater applied to mathematical reasoning: it optimizes for looking rigorous, not for being rigorous.
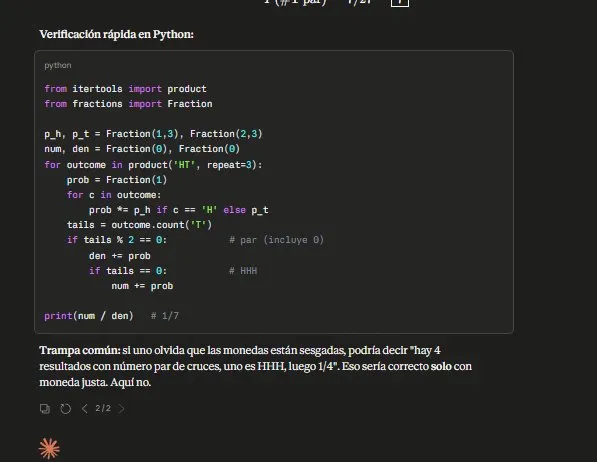
Two: the decorative code. At level 3, it wrote a correct Python block (which if executed would yield 1/13) with a comment # 1/7 at the end. It wrote code that contradicts its own answer and fabricated the comment about what it would return. When you force it to actually execute, it acknowledges the error:
“Lesson well deserved: writing ‘decorative’ code without executing it defeats its purpose.”
It literally admits the mechanism in writing. And still reproduces it when execution isn’t forced.
Three: the capability exists but doesn’t self-activate. At level 5, when you say “there’s a trap, find the word,” it reaches 0 effortlessly. Solves systems of equations, sets up joint distributions, discards independence elegantly. The capability is there. But it only fires when the human places the answer at the end of the funnel.
In real use, nobody’s going to tell you “watch out, this email has a trap” or “this SQL query assumes something that doesn’t hold”. A model’s utility lies in detecting the trap without anyone pointing it out. And there, consistently, it fails.
The deeper thesis
Current models scale along the rigor axis: more steps, more verification, more structured reasoning. They don’t scale along the distrust of the premise axis.
Thinking more doesn’t get you closer to questioning the premise. You can add thinking, verification, real code execution — and the model keeps operating within the initial frame. It becomes more consistent at solving the wrong problem.
It’s the same dynamic as a university exam: a student who studies more doesn’t necessarily catch the trick question — they can perfectly solve the problem they thought they read. Only the student who reads with suspicion catches the trap. And “reading with suspicion” isn’t an axis that scales with effort; it’s a different mental mode.
The finding that hurts
Back to the car wash. I have a memory instruction in Claude that essentially says, “understand the goal of the question before answering.” It’s not a stored answer for this specific case — it’s a method instruction.
In 4.7, that memory arrives partially. Proof: the model uses my nickname — that comes from memory. But the method instruction has no effect. The adaptive thinking router decides before memory can operate.
This restructures everything. It’s not the first time a silent change broke what was working — it already happened with Claude Code’s silent downgrade. But here the problem runs deeper. The levers you had to force rigor have lost their power without notice:
- Forced Extended thinking → no longer an exposed lever (replaced by adaptive)
- Method instructions in memory → reach the model but don’t activate deep reasoning
- Carefully crafted system prompts → applied during generation, when the frame has already been set
All the investment you’ve made curating memory, fine-tuning guardrails, building workflows with previous models — no longer guarantees the behavior it guaranteed. The implicit contract between user and model has been silently broken. No error. No warning. Things that used to work stop working.
And you don’t know where they’re failing until you test them one by one.
Corollary: the muscle you can’t delegate
All of this reinforces something I’ve been practicing for weeks: the Solo Ticket. One ticket per week without an LLM. It’s not nostalgia for when we coded without AI — it’s specific training for the muscle that models can’t lend you: distrust of the premise.
When you use an LLM to solve a ticket, the LLM solves it well. The thing is, it solves it well for the problem it thinks you’re asking. If you stop being the one who questions the framing, nobody questions it. The result is code that works perfectly for the wrong problem.
A student who always passes with AI gets a B+. Never an A. And more importantly, they stop developing the muscle that separates someone who passes easily from someone who aces it. That muscle is what separates a senior engineer from a junior one who uses AI.
With 4.5 Extended, you could partially compensate: forcing the model to think seriously was a way to externalize the distrust. With 4.7 adaptive, not even that. The only way out is to keep your own muscle sharp.
Prompts used to reproduce the experiments:
- Coins: “Three coins are tossed. Each coin has P(H) = 1/3. It is known that the number of tails is always even. What is the probability that all three show heads?”
- Car wash: “I want to wash my car and the car wash is 50 meters away. Do I drive or walk?”
If you run these and get different results, I’d like to hear about it. These failures depend on the exact internal router configuration, which can change over time.
Keep exploring
- LLM sycophancy: AIs that just agree with you — When the model would rather agree than question your premise
- The model can reason. It won’t commit — Capability without commitment: another angle on the same problem
- Don’t be a model fanboy — Why locking yourself to a provider leaves you exposed to exactly this
Related course
Learn AI Development Master with real practice
Step-by-step modules, hands-on exercises and real projects. No fluff.
See course →Consulting
Got a similar problem with AI Integrations?
I can help. Tell me what you're dealing with and I'll give you an honest diagnosis — no commitment.
See consulting →You might also like
Claude Opus 4.6: the model that tanked the market
Claude Opus 4.6 brings 1M context and agent teams. Cowork plugins wiped $285B off software stocks. What changed and why it matters.
Taxonomy of LLM failures
Language models fail in four distinct ways. Each requires a different fix: prompt tuning, RAG, fine-tuning, or guardrails. A practical taxonomy.
The model knows how to reason. It just won't commit
17 prompt iterations revealed that the model finds the correct answer but self-censors for not being standard